Why is it important to understand the potential value UiPath Communications Mining can enable prior to training?
What does the Label Trends table in UiPath Communications Mining show?
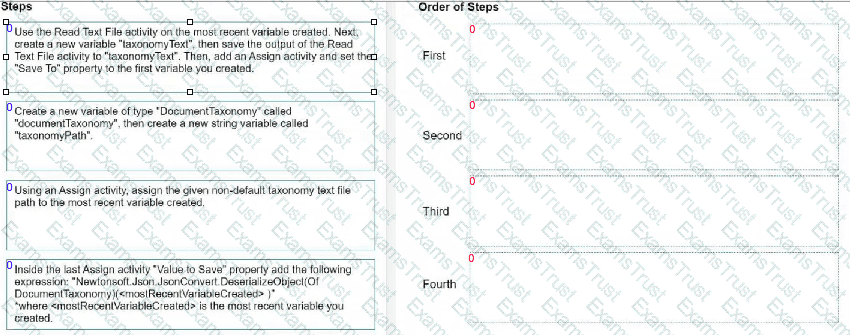
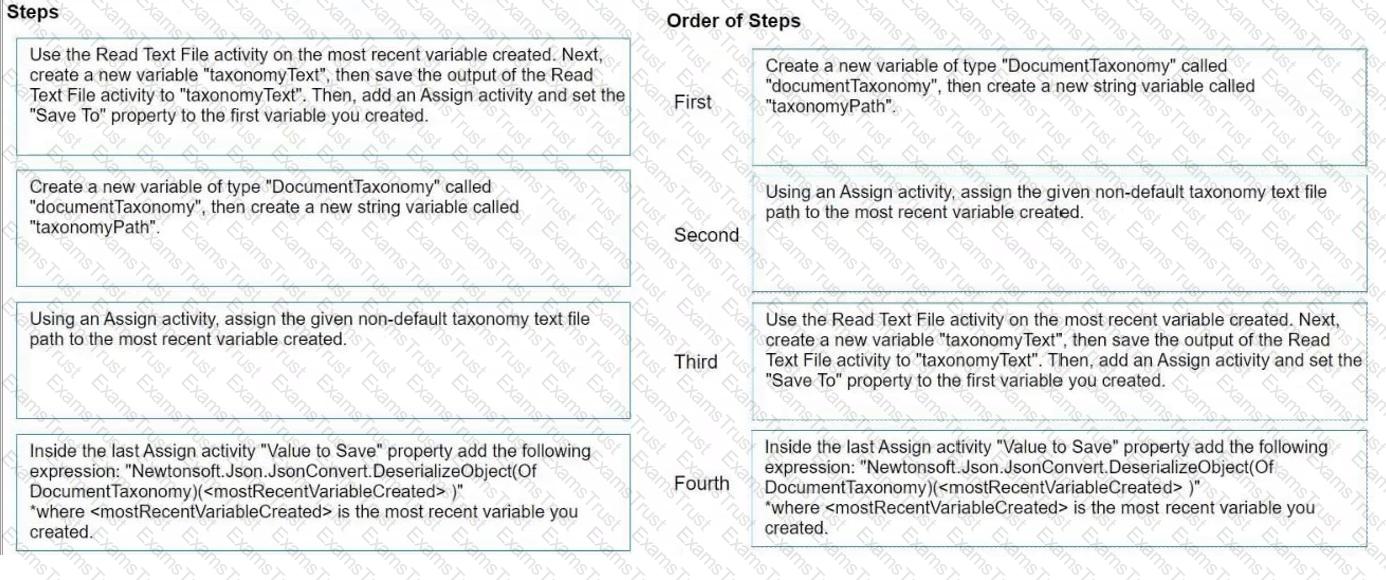
How do you load a taxonomy from a given non-default location text file into a variable?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct order.
What can be done in the Reports section of the dataset navigation bar in UiPath Communication Mining?
Where should a model be pinned in UiPath Communications Mining?
Which environment variable is relevant for Evaluation pipelines?
A developer has created a string array variable as shown below:
UserNames = {"Jane", "Jack", "Jill", "John"}
Which expression should the developer use in a Log Message activity to print the elements of the array separated by the string ","?
When dealing with variable-length data, or data spanning over multiple pages of the document (e.g. item tables), what is the recommended data extraction methodology to be used?
Which of the following consumes Page Units?
What will be the outcome when executing a Try Catch activity with a sequence placed within the Try section and no Catches section present?
What is the difference between OCR (Optical Character Recognition) and IntelligentOCR?
What are the available options for Scoring in Document Manager, that apply to string fields only?
How do you use the Generative Classifier within UiPath Document Understanding Cloud APIs to classify a document as either an "Invoice" or a "Receipt"?
What are the out-of-the-box packages types available in Al Center?
Can a custom-built extractor be used in the Data Extraction Scope activity?
What happens to your document and the process of pre-labeling when you choose the "Predict" option from the "Predict" dropdown in Document Manager?
How do the prediction mechanisms for labels and general fields differ in the UiPath Communications Mining platform?
What is the recommended number of documents per vendor to train the initial dataset?
Which of the following is true when creating an ML Package in UiPath Al Center?
Which of the following are unstructured documents?
In a Document Understanding project, the user needs to extract information from PDF documents with the following requirements:
The documents can contain scanned or digitally typed text.
The documents can contain checkboxes, and these must be extracted.
The automation must use the logical processors in the most efficient way to obtain the maximum degree of parallelism.What are the properties provided to the Digitize Document activity in the Digitize phase?
What is OCR (Optical Character Recognition)?
As a best practice, who should perform the data labeling?
Which role is responsible for building and uploading ML (Machine Learning) models lo Al Center?
When is it recommended to use an ML (Machine Learning) model solution?
How can a Pipeline be scheduled?
What are the available options for Scoring in Document Manager, that apply only to string content type?
While creating a process automation pipeline, what process attribute should be avoided to ensure there are minimal or no automation maintenance requirements?
What is the purpose of the End Process in the Document Understanding Process?
In which of the following scenarios, the ML Classifier is the only recommended classifier to be used, according to best practice?
What role do Triggers play in the UiPath Integration Service?
Why is the Shuffle training mode important in the "Explore" phase while working with UiPath Communications Mining?
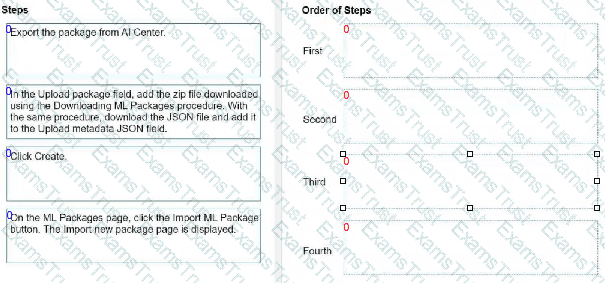
What is the correct order of uploading a package exported from UiPath AI Center?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct order.
Which of the following extractors can be used for Data Extraction Scope activity?
What can be found in the Images folder within the exported dataset coming from Document Manager?
Which of the following statements is correct in the context of migrating a schema from Document Manager to a Modern Project?
What is the Machine Learning Extractor?
Which is the correct description of the Configure Extractors Wizard?
What is Document Understanding?
Which of the following data structures in a UiPath workflow allow dynamic resizing, making it suitable for scenarios where the number of elements is not predetermined?
Which of the following options is accepted as a Column field name in Document Manager?
Why is it important to gather and analyze data about the languages in scope?
Which is the most suitable extractor for extracting data from invoices from different customers?
Why is having high coverage important for an automation-focused use case in UiPath Communications Mining?
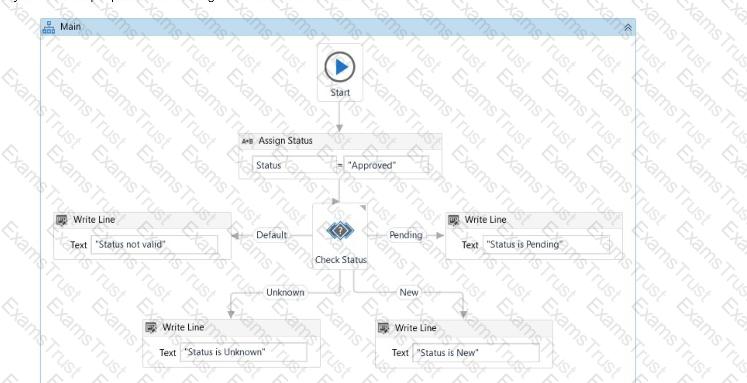
What will be displayed in the Output panel after running the workflow below?
Which activity is used to validate and correct automatic classification outputs?
What is the name of the web application that allows users to prepare, review, and make corrections to datasets required for Machine Learning models?
Which activity should be used for classification validation in attended mode?
What is the main purpose of the Document Understanding Process template in UiPath Studio?
Which are the the minimum required inputs in order to configure the Validation Station as an attended activity?
What is the purpose of the One Click Classification feature in the UiPath Document Understanding interface?
What is a reason for pinning a UiPath Communications Mining Model?
On at least how many different pages should a regular field be labeled in Data Manager before Exporting the labeled documents to Al Center?
How is the Taxonomy component used in the Document Understanding Template?
What function in the train.py file is responsible for persisting the trained model?
In UiPath Communications Mining, which phase is the starting point of the model training process, where similar intents and conversation themes are grouped?
The "Train" stage from Document Understanding Framework usually comes after?
What is one of the purposes of the Config file in the UiPath Document Understanding Template?
What is the role of connections in the UiPath Integration Service?
Which are all the options for managing ML Skills?
Which of the following is a characteristic of a poorly-performing model in UiPath Communications Mining?
Which features in Generative Annotation are automatically enabled on datasets in Communication Mining technology?
A project contains a Try Catch activity in the "Main.xaml" workflow. In the Catches block, there is a Rethrow activity. The process is started from Orchestrator and an exception is caught in the Trysection. What is the expected result?
Which of the following use cases is best suited for tone analysis instead of label sentiment analysis in UiPath Communications Mining?
What are the three types of classifier trainers available in packages UiPath.lntelligentOCR.Activities and UiPath.DocumentUnderstanding.ML.Activities?
In the general fields training, what actions does the Communications Mining Train feature guide you through?
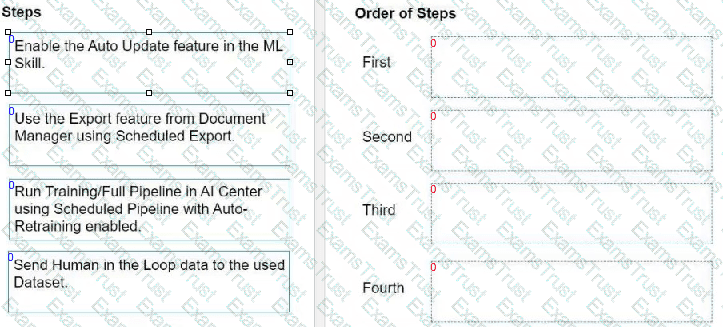
What is the order of steps for automatically retraining and deploying a Document Understanding ML Model in Al Center with data from Document Validation Action?
Instructions: Drag the steps found on the "Left" and drop them on the "Right" in the correct order.
For what type of documents is it recommended to use the RegEx Based Extractor?
If Label X in UiPath Communications Mining has 80% precision at a given confidence threshold, what output should this provide?
What is the definition of Deep Learning?
What is the default visibility of an ML skill?
What are all the types of ML (Machine Learning) models supported by Al Center?
What components are part of the Document Understanding Process template?
What is the Document Object Model (DOM) in the context of Document Understanding?
What is the primary advantage of the One Click Extraction feature in UiPath's Document Understanding interface?

 A close-up of a page
AI-generated content may be incorrect.
A close-up of a page
AI-generated content may be incorrect.
 A screenshot of a computer
AI-generated content may be incorrect.
A screenshot of a computer
AI-generated content may be incorrect.
 A screenshot of a computer
AI-generated content may be incorrect.
A screenshot of a computer
AI-generated content may be incorrect.