Click the Exhibit button.
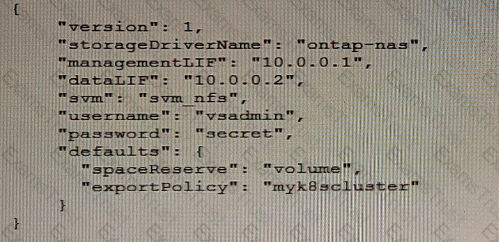
Referring to the exhibit, you are certain that the backend configuration information is correct, but you still cannot get the created PVCs to connect.
What are three reasons for this problem? (Choose three.)
Click the Exhibit button.
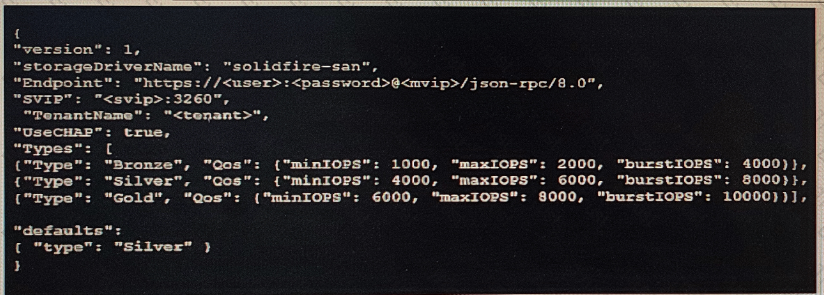
Refer to the exhibit and the Storage Class information shown below.

What are the minimum IOPS, maximum IOPS, and burst IOPS assigned to the persistent volumes that were created by Trident?
A customer made a mistake and deleted some important notes in their Jupyter notebooks. The customer wants to perform a near-instantaneous restore of a specific snapshot for a JupyterLab workspace.
Which command in the NetApp DataOps Toolkit will accomplish this task?
Your organization is adopting DevOps techniques to accelerate the release times of your product. The organization wants to have more communication between teams, quick iterations, and a better method for training work in progress.
In this scenario, which three methodologies would you recommend? (Choose three.)
You are using Nvidia DeepOps to deploy Kubernetes clusters on top of NetApp ONTAP AI systems. In this scenario, which automation engine is required?
As a DevOps engineer, you want a single tool that uses one automation language consistently across orchestration, application deployment, and configuration management.
In this scenario, which tool would you choose?
You have a StorageGRID solution with 1 PB of object data. All data is geographically distributed and erasure coded across three sites. You are asked to create a new information lifecycle management (ILM) policy that will keep a full copy of the grid in Amazon S3.
In this scenario, which component must be configured for the ILM policy?
You used a Terraform configuration to create a number of resources in Google Cloud for testing your applications. You have completed the tests and you no longer need the infrastructure. You want to delete all of the resources and save costs.
In this scenario, which command would you use to satisfy the requirements?
Your customer is running their Kafka and Spark applications inside a Kubernetes cluster. They want to create a single backup policy within Astra to automate the backup of both applications and all their related Kubernetes objects at the same time.
Which method in Kubernetes should be used to accomplish this task?