39 of 55.
A Spark developer is developing a Spark application to monitor task performance across a cluster.
One requirement is to track the maximum processing time for tasks on each worker node and consolidate this information on the driver for further analysis.
Which technique should the developer use?
5 of 55.
What is the relationship between jobs, stages, and tasks during execution in Apache Spark?
A data engineer is building a Structured Streaming pipeline and wants the pipeline to recover from failures or intentional shutdowns by continuing where the pipeline left off.
How can this be achieved?
49 of 55.
In the code block below, aggDF contains aggregations on a streaming DataFrame:
aggDF.writeStream \
.format("console") \
.outputMode("???") \
.start()
Which output mode at line 3 ensures that the entire result table is written to the console during each trigger execution?
Which command overwrites an existing JSON file when writing a DataFrame?
Given this code:

.withWatermark("event_time", "10 minutes")
.groupBy(window("event_time", "15 minutes"))
.count()
What happens to data that arrives after the watermark threshold?
Options:
A Spark engineer must select an appropriate deployment mode for the Spark jobs.
What is the benefit of using cluster mode in Apache Spark™?
A DataFrame df has columns name, age, and salary. The developer needs to sort the DataFrame by age in ascending order and salary in descending order.
Which code snippet meets the requirement of the developer?
36 of 55.
What is the main advantage of partitioning the data when persisting tables?
An engineer notices a significant increase in the job execution time during the execution of a Spark job. After some investigation, the engineer decides to check the logs produced by the Executors.
How should the engineer retrieve the Executor logs to diagnose performance issues in the Spark application?
A data scientist has identified that some records in the user profile table contain null values in any of the fields, and such records should be removed from the dataset before processing. The schema includes fields like user_id, username, date_of_birth, created_ts, etc.
The schema of the user profile table looks like this:

Which block of Spark code can be used to achieve this requirement?
Options:
23 of 55.
A data scientist is working with a massive dataset that exceeds the memory capacity of a single machine. The data scientist is considering using Apache Spark™ instead of traditional single-machine languages like standard Python scripts.
Which two advantages does Apache Spark™ offer over a normal single-machine language in this scenario? (Choose 2 answers)
A data scientist is working with a Spark DataFrame called customerDF that contains customer information. The DataFrame has a column named email with customer email addresses. The data scientist needs to split this column into username and domain parts.
Which code snippet splits the email column into username and domain columns?
A data engineer replaces the exact percentile() function with approx_percentile() to improve performance, but the results are drifting too far from expected values.
Which change should be made to solve the issue?

A Spark application is experiencing performance issues in client mode because the driver is resource-constrained.
How should this issue be resolved?
42 of 55.
A developer needs to write the output of a complex chain of Spark transformations to a Parquet table called events.liveLatest.
Consumers of this table query it frequently with filters on both year and month of the event_ts column (a timestamp).
The current code:
from pyspark.sql import functions as F
final = df.withColumn("event_year", F.year("event_ts")) \
.withColumn("event_month", F.month("event_ts")) \
.bucketBy(42, ["event_year", "event_month"]) \
.saveAsTable("events.liveLatest")
However, consumers report poor query performance.
Which change will enable efficient querying by year and month?
A developer is running Spark SQL queries and notices underutilization of resources. Executors are idle, and the number of tasks per stage is low.
What should the developer do to improve cluster utilization?
A data engineer is reviewing a Spark application that applies several transformations to a DataFrame but notices that the job does not start executing immediately.
Which two characteristics of Apache Spark's execution model explain this behavior?
Choose 2 answers:
9 of 55.
Given the code fragment:
import pyspark.pandas as ps
pdf = ps.DataFrame(data)
Which method is used to convert a Pandas API on Spark DataFrame (pyspark.pandas.DataFrame) into a standard PySpark DataFrame (pyspark.sql.DataFrame)?
Given this view definition:
df.createOrReplaceTempView("users_vw")
Which approach can be used to query the users_vw view after the session is terminated?
Options:
A data engineer is running a Spark job to process a dataset of 1 TB stored in distributed storage. The cluster has 10 nodes, each with 16 CPUs. Spark UI shows:
Low number of Active Tasks
Many tasks complete in milliseconds
Fewer tasks than available CPUs
Which approach should be used to adjust the partitioning for optimal resource allocation?
A Spark engineer is troubleshooting a Spark application that has been encountering out-of-memory errors during execution. By reviewing the Spark driver logs, the engineer notices multiple "GC overhead limit exceeded" messages.
Which action should the engineer take to resolve this issue?
19 of 55.
A Spark developer wants to improve the performance of an existing PySpark UDF that runs a hash function not available in the standard Spark functions library.
The existing UDF code is:
import hashlib
from pyspark.sql.types import StringType
def shake_256(raw):
return hashlib.shake_256(raw.encode()).hexdigest(20)
shake_256_udf = udf(shake_256, StringType())
The developer replaces this UDF with a Pandas UDF for better performance:
@pandas_udf(StringType())
def shake_256(raw: str) -> str:
return hashlib.shake_256(raw.encode()).hexdigest(20)
However, the developer receives this error:
TypeError: Unsupported signature: (raw: str) -> str
What should the signature of the shake_256() function be changed to in order to fix this error?
47 of 55.
A data engineer has written the following code to join two DataFrames df1 and df2:
df1 = spark.read.csv("sales_data.csv")
df2 = spark.read.csv("product_data.csv")
df_joined = df1.join(df2, df1.product_id == df2.product_id)
The DataFrame df1 contains ~10 GB of sales data, and df2 contains ~8 MB of product data.
Which join strategy will Spark use?
14 of 55.
A developer created a DataFrame with columns color, fruit, and taste, and wrote the data to a Parquet directory using:
df.write.partitionBy("color", "taste").parquet("/path/to/output")
What is the result of this code?
A data engineer needs to write a DataFrame df to a Parquet file, partitioned by the column country, and overwrite any existing data at the destination path.
Which code should the data engineer use to accomplish this task in Apache Spark?
34 of 55.
A data engineer is investigating a Spark cluster that is experiencing underutilization during scheduled batch jobs.
After checking the Spark logs, they noticed that tasks are often getting killed due to timeout errors, and there are several warnings about insufficient resources in the logs.
Which action should the engineer take to resolve the underutilization issue?
A data analyst builds a Spark application to analyze finance data and performs the following operations: filter, select, groupBy, and coalesce.
Which operation results in a shuffle?
A Spark DataFrame df is cached using the MEMORY_AND_DISK storage level, but the DataFrame is too large to fit entirely in memory.
What is the likely behavior when Spark runs out of memory to store the DataFrame?
46 of 55.
A data engineer is implementing a streaming pipeline with watermarking to handle late-arriving records.
The engineer has written the following code:
inputStream \
.withWatermark("event_time", "10 minutes") \
.groupBy(window("event_time", "15 minutes"))
What happens to data that arrives after the watermark threshold?
44 of 55.
A data engineer is working on a real-time analytics pipeline using Spark Structured Streaming.
They want the system to process incoming data in micro-batches at a fixed interval of 5 seconds.
Which code snippet fulfills this requirement?
17 of 55.
A data engineer has noticed that upgrading the Spark version in their applications from Spark 3.0 to Spark 3.5 has improved the runtime of some scheduled Spark applications.
Looking further, the data engineer realizes that Adaptive Query Execution (AQE) is now enabled.
Which operation should AQE be implementing to automatically improve the Spark application performance?
1 of 55. A data scientist wants to ingest a directory full of plain text files so that each record in the output DataFrame contains the entire contents of a single file and the full path of the file the text was read from.
The first attempt does read the text files, but each record contains a single line. This code is shown below:
txt_path = "/datasets/raw_txt/*"
df = spark.read.text(txt_path) # one row per line by default
df = df.withColumn("file_path", input_file_name()) # add full path
Which code change can be implemented in a DataFrame that meets the data scientist's requirements?
38 of 55.
A data engineer is working with Spark SQL and has a large JSON file stored at /data/input.json.
The file contains records with varying schemas, and the engineer wants to create an external table in Spark SQL that:
Reads directly from /data/input.json.
Infers the schema automatically.
Merges differing schemas.
Which code snippet should the engineer use?
10 of 55.
What is the benefit of using Pandas API on Spark for data transformations?
4 of 55.
A developer is working on a Spark application that processes a large dataset using SQL queries. Despite having a large cluster, the developer notices that the job is underutilizing the available resources. Executors remain idle for most of the time, and logs reveal that the number of tasks per stage is very low. The developer suspects that this is causing suboptimal cluster performance.
Which action should the developer take to improve cluster utilization?
40 of 55.
A developer wants to refactor older Spark code to take advantage of built-in functions introduced in Spark 3.5.
The original code:
from pyspark.sql import functions as F
min_price = 110.50
result_df = prices_df.filter(F.col("price") > min_price).agg(F.count("*"))
Which code block should the developer use to refactor the code?
A data engineer needs to write a Streaming DataFrame as Parquet files.
Given the code:

Which code fragment should be inserted to meet the requirement?
A)

B)

C)
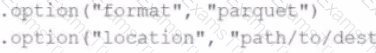
D)

Which code fragment should be inserted to meet the requirement?
A developer notices that all the post-shuffle partitions in a dataset are smaller than the value set for spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold.
Which type of join will Adaptive Query Execution (AQE) choose in this case?
The following code fragment results in an error:
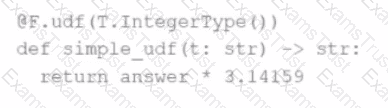
Which code fragment should be used instead?
A)

B)

C)

D)
