A data scientist is using the following confusion matrix to assess model performance:
Actually Fails
Actually Succeeds
Predicted to Fail
80%
20%
Predicted to Succeed
15%
85%

The model is predicting whether a delivery truck will be able to make 200 scheduled delivery stops.
Every time the model is correct, the company saves 1 hour in planning and scheduling.
Every time the model is wrong, the company loses 4 hours of delivery time.
Which of the following is the net model impact for the company?
Which of the following best describes the minimization of the residual term in a LASSO linear regression?
A model's results show increasing explanatory value as additional independent variables are added to the model. Which of the following is the most appropriate statistic?
A data scientist is standardizing a large data set that contains website addresses. A specific string inside some of the web addresses needs to be extracted. Which of the following is the best method for extracting the desired string from the text data?
A data scientist is working with a data set that covers a two-year period for a large number of machines. The data set contains:
Machine system ID numbers
Sensor measurement values
Daily timestamps for each machine
The data scientist needs to plot the total measurements from all the machines over the entire time period. Which of the following is the best way to present this data?
Which of the following is best solved with graph theory?
A company created a very popular collectible card set. Collectors attempt to collect the entire set, but the availability of each card varies, because some cards have higher production volumes than others. The set contains a total of 12 cards. The attributes of the cards are shown.
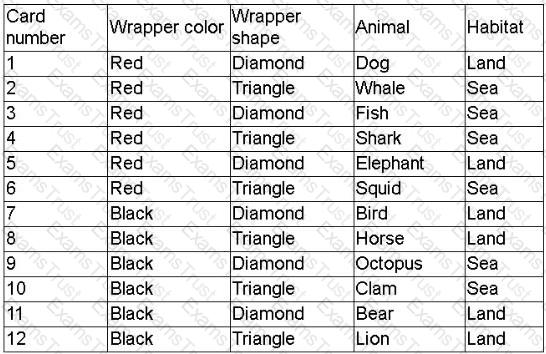
The data scientist is tasked with designing an initial model iteration to predict whether the animal on the card lives in the sea or on land, given the card's features: Wrapper color, Wrapper shape, and Animal.
Which of the following is the best way to accomplish this task?
The term "greedy algorithms" refers to machine-learning algorithms that:
A data scientist is building a proof of concept for a commercialized machine-learning model. Which of the following is the best starting point?
An analyst wants to show how the component pieces of a company's business units contribute to the company's overall revenue. Which of the following should the analyst use to best demonstrate this breakdown?
A data scientist is preparing to brief a non-technical audience that is focused on analysis and results. During the modeling process, the data scientist produced the following artifacts:
Which of the following artifacts should the data scientist include in the briefing? (Choose two.)
Which of the following is the naive assumption in Bayes' rule?
A data scientist is performing a linear regression and wants to construct a model that explains the most variation in the data. Which of the following should the data scientist maximize when evaluating the regression performance metrics?
A data scientist is merging two tables. Table 1 contains employee IDs and roles. Table 2 contains employee IDs and team assignments. Which of the following is the best technique to combine these data sets?
Which of the following best describes the minimization of the residual term in a ridge linear regression?
A data scientist is presenting the recommendations from a monthslong modeling and experiment process to the company’s Chief Executive Officer. Which of the following is the best set of artifacts to include in the presentation?
A data analyst wants to generate the most data using tables from a database. Which of the following is the best way to accomplish this objective?
A data scientist is designing a real-time machine-learning model that classifies a user based on initial behavior. The run times of these models are provided in the following table:

Which of the following models should the data scientist recommend for deployment?
Which of the following belong in a presentation to the senior management team and/or C-suite executives? (Choose two.)
An analyst is examining data from an array of temperature sensors and sees that one sensor consistently returns values that are much higher than the values from the other sensors. Which of the following terms best describes this type of error?
A data analyst wants to use compression on an analyzed data set and send it to a new destination for further processing. Which of the following issues will most likely occur?
Which of the following distributions would be best to use for hypothesis testing on a data set with 20 observations?
A data scientist wants to digitize historical hard copies of documents. Which of the following is the best method for this task?
A data scientist is deploying a model that needs to be accessed by multiple departments with minimal development effort by the departments. Which of the following APIs would be best for the data scientist to use?
A data scientist has constructed a model that meets the minimum performance requirements specified in the proposal for a prediction project. The data scientist thinks the model's accuracy should be improved, but the proposed deadline is approaching. Which of the following actions should the data scientist take first?