Which of the following describes a neural network without an activation function?
Why do data skews happen in the ML pipeline?
When working with textual data and trying to classify text into different languages, which approach to representing features makes the most sense?
Which of the following is a privacy-focused law that an AI practitioner should adhere to while designing and adapting an AI system that utilizes personal data?
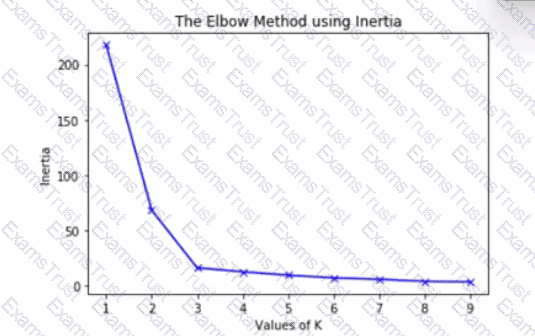
The graph is an elbow plot showing the inertia or within-cluster sum of squares on the y-axis and number of clusters (also called K) on the x-axis, denoting the change in inertia as the clusters change using k-means algorithm.
What would be an optimal value of K to ensure a good number of clusters?
Which of the following is a common negative side effect of not using regularization?
Your dependent variable data is a proportion. The observed range of your data is 0.01 to 0.99. The instrument used to generate the dependent variable data is known to generate low quality data for values close to 0 and close to 1. A colleague suggests performing a logit-transformation on the data prior to performing a linear regression. Which of the following is a concern with this approach?
Definition of logit-transformation
If p is the proportion: logit(p)=log(p/(l-p))
A product manager is designing an Artificial Intelligence (AI) solution and wants to do so responsibly, evaluating both positive and negative outcomes.
The team creates a shared taxonomy of potential negative impacts and conducts an assessment along vectors such as severity, impact, frequency, and likelihood.
Which modeling technique does this team use?
Which of the following pieces of AI technology provides the ability to create fake videos?
Which of the following is a type 1 error in statistical hypothesis testing?
Which of the following is the correct definition of the quality criteria that describes completeness?
You have a dataset with many features that you are using to classify a dependent variable. Because the sample size is small, you are worried about overfitting. Which algorithm is ideal to prevent overfitting?
Which of the following unsupervised learning models can a bank use for fraud detection?
Which of the following are true about the transform-design pattern for a machine learning pipeline? (Select three.)
It aims to separate inputs from features.
When should you use semi-supervised learning? (Select two.)
A big data architect needs to be cautious about personally identifiable information (PII) that may be captured with their new IoT system. What is the final stage of the Data Management Life Cycle, which the architect must complete in order to implement data privacy and security appropriately?
Normalization is the transformation of features:
Which of the following sentences is true about model evaluation and model validation in ML pipelines?
A classifier has been implemented to predict whether or not someone has a specific type of disease. Considering that only 1% of the population in the dataset has this disease, which measures will work the BEST to evaluate this model?
For each of the last 10 years, your team has been collecting data from a group of subjects, including their age and numerous biomarkers collected from blood samples. You are tasked with creating a prediction model of age using the biomarkers as input. You start by performing a linear regression using all of the data over the 10-year period, with age as the dependent variable and the biomarkers as predictors.
Which assumption of linear regression is being violated?
You train a neural network model with two layers, each layer having four nodes, and realize that the model is underfit. Which of the actions below will NOT work to fix this underfitting?
You are building a prediction model to develop a tool that can diagnose a particular disease so that individuals with the disease can receive treatment. The treatment is cheap and has no side effects. Patients with the disease who don't receive treatment have a high risk of mortality.
It is of primary importance that your diagnostic tool has which of the following?
Which of the following sentences is TRUE about the definition of cloud models for machine learning pipelines?
You create a prediction model with 96% accuracy. While the model's true positive rate (TPR) is performing well at 99%, the true negative rate (TNR) is only 50%. Your supervisor tells you that the TNR needs to be higher, even if it decreases the TPR. Upon further inspection, you notice that the vast majority of your data is truly positive.
What method could help address your issue?
Which of the following options is a correct approach for scheduling model retraining in a weather prediction application?
Which two techniques are used to build personas in the ML development lifecycle? (Select two.)
Which of the following is the primary purpose of hyperparameter optimization?