You add an index on the searched field of a MySQL table with many rows (>100k). The field would benefit greatly from the index in which three scenarios?
The field contains a textual short business code.
The field contains long unstructured text such as a hash.
The field contains many datetimes, covering a large range.
The field contains big integers, above and below 0.
The field contains a structured JSON.
Comprehensive and Detailed In-Depth Explanation:
Adding an index to a searched field in a MySQL table with over 100,000 rows improves query performance by reducing the number of rows scanned during searches, joins, or filters. The benefit of an index depends on the field’s data type, cardinality (uniqueness), and query patterns. MySQL indexing best practices, as aligned with Appian’s Database Optimization Guidelines, highlight scenarios where indices are most effective.
Option A (The field contains a textual short business code):This benefits greatly from an index. A short business code (e.g., a 5-10 character identifier like "CUST123") typically has high cardinality (many unique values) and is often used in WHERE clauses or joins. An index on this field speeds up exact-match queries (e.g., WHERE business_code = 'CUST123'), which are common in Appian applications for lookups or filtering.
Option C (The field contains many datetimes, covering a large range):This is highly beneficial. Datetime fields with a wide range (e.g., transaction timestamps over years) are frequently queried with range conditions (e.g., WHERE datetime BETWEEN '2024-01-01' AND '2025-01-01') or sorting (e.g., ORDER BY datetime). An index on this field optimizes these operations, especially in large tables, aligning with Appian’s recommendation to index time-based fields for performance.
Option D (The field contains big integers, above and below 0):This benefits significantly. Big integers (e.g., IDs or quantities) with a broad range and high cardinality are ideal for indexing. Queries like WHERE id > 1000 or WHERE quantity < 0 leverage the index for efficient range scans or equality checks, a common pattern in Appian data store queries.
Option B (The field contains long unstructured text such as a hash):This benefits less. Long unstructured text (e.g., a 128-character SHA hash) has high cardinality but is less efficient for indexing due to its size. MySQL indices on large text fields can slow down writes and consume significant storage, and full-text searches are better handled with specialized indices (e.g., FULLTEXT), not standard B-tree indices. Appian advises caution with indexing large text fields unless necessary.
Option E (The field contains a structured JSON):This is minimally beneficial with a standard index. MySQL supports JSON fields, but a regular index on the entire JSON column is inefficient for large datasets (>100k rows) due to its variable structure. Generated columns or specialized JSON indices (e.g., using JSON_EXTRACT) are required for targeted queries (e.g., WHERE JSON_EXTRACT(json_col, '$.key') = 'value'), but this requires additional setup beyond a simple index, reducing its immediate benefit.
For a table with over 100,000 rows, indices are most effective on fields with high selectivity and frequent query usage (e.g., short codes, datetimes, integers), making A, C, and D the optimal scenarios.
For each requirement, match the most appropriate approach to creating or utilizing plug-ins Each approach will be used once.
Note: To change your responses, you may deselect your response by clicking the blank space at the top of the selection list.

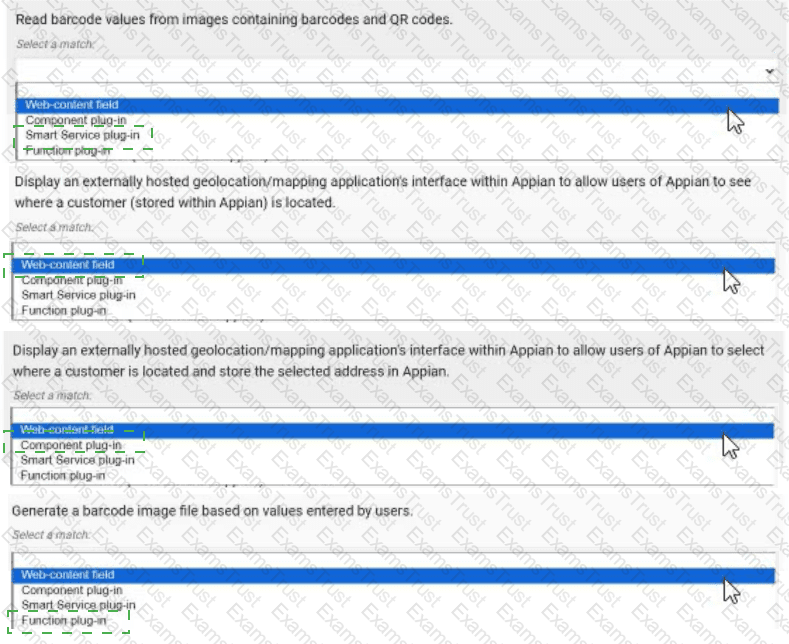
Read barcode values from images containing barcodes and QR codes. → Smart Service plug-in
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to see where a customer (stored within Appian) is located. → Web-content field
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to select where a customer is located and store the selected address in Appian. → Component plug-in
Generate a barcode image file based on values entered by users. → Function plug-in
Comprehensive and Detailed In-Depth Explanation:
Appian plug-ins extend functionality by integrating custom Java code into the platform. The four approaches—Web-content field, Component plug-in, Smart Service plug-in, and Function plug-in—serve distinct purposes, and each requirement must be matched to the most appropriate one based on its use case. Appian’s Plug-in Development Guide provides the framework for these decisions.
Read barcode values from images containing barcodes and QR codes → Smart Service plug-in:This requirement involves processing image data to extract barcode or QR code values, a task that typically occurs within a process model (e.g., as part of a workflow). A Smart Service plug-in is ideal because it allows custom Java logic to be executed as a node in a process, enabling the decoding of images and returning the extracted values to Appian. This approach integrates seamlessly with Appian’s process automation, making it the best fit for data extraction tasks.
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to see where a customer (stored within Appian) is located → Web-content field:This requires embedding an external mapping interface (e.g., Google Maps) within an Appian interface. A Web-content field is the appropriate choice, as it allows you to embed HTML, JavaScript, or iframe content from an external source directly into an Appian form or report. This approach is lightweight and does not require custom Java development, aligning with Appian’s recommendation for displaying external content without interactive data storage.
Display an externally hosted geolocation/mapping application’s interface within Appian to allow users of Appian to select where a customer is located and store the selected address in Appian → Component plug-in:This extends the previous requirement by adding interactivity (selecting an address) and data storage. A Component plug-in is suitable because it enables the creation of a custom interface component (e.g., a map selector) that can be embedded in Appian interfaces. The plug-in can handle user interactions, communicate with the external mapping service, and update Appian data stores, offering a robust solution for interactive external integrations.
Generate a barcode image file based on values entered by users → Function plug-in:This involves generating an image file dynamically based on user input, a task that can be executed within an expression or interface. A Function plug-in is the best match, as it allows custom Java logic to be called as an expression function (e.g., pluginGenerateBarcode(value)), returning the generated image. This approach is efficient for single-purpose operations and integrates well with Appian’s expression-based design.
Matching Rationale:
Each approach is used once, as specified, covering the spectrum of plug-in types: Smart Service for process-level tasks, Web-content field for static external display, Component plug-in for interactive components, and Function plug-in for expression-level operations.
Appian’s plug-in framework discourages overlap (e.g., using a Smart Service for display or a Component for process tasks), ensuring the selected matches align with intended use cases.
You are asked to design a case management system for a client. In addition to storing some basic metadata about a case, one of the client’s requirements is the ability for users to update a case. The client would like any user in their organization of 500 people to be able to make these updates. The users are all based in the company's headquarters, and there will be frequent cases where users are attempting to edit the same case. The client wants to ensure no information is lost when these edits occur and does not want the solution to burden their process administrators with any additional effort. Which data locking approach should you recommend?
Allow edits without locking the case CDI.
Use the database to implement low-level pessimistic locking.
Add an @Version annotation to the case CDT to manage the locking.
Design a process report and query to determine who opened the edit form first.
Comprehensive and Detailed In-Depth Explanation:
The requirement involves a case management system where 500 users may simultaneously edit the same case, with a need to prevent data loss and minimize administrative overhead. Appian’s data management and concurrency control strategies are critical here, especially when integrating with an underlying database.
Option C (Add an @Version annotation to the case CDT to manage the locking):This is the recommended approach. In Appian, the @Version annotation on a Custom Data Type (CDT) enables optimistic locking, a lightweight concurrency control mechanism. When a user updates a case, Appian checks the version number of the CDT instance. If another user has modified it in the meantime, the update fails, prompting the user to refresh and reapply changes. This prevents data loss without requiring manual intervention by process administrators. Appian’s Data Design Guide recommends @Version for scenarios with high concurrency (e.g., 500 users) and frequent edits, as it leverages the database’s native versioning (e.g., in MySQL or PostgreSQL) and integrates seamlessly with Appian’s process models. This aligns with the client’s no-burden requirement.
Option A (Allow edits without locking the case CDI):This is risky. Without locking, simultaneous edits could overwrite each other, leading to data loss—a direct violation of the client’s requirement. Appian does not recommend this for collaborative environments.
Option B (Use the database to implement low-level pessimistic locking):Pessimistic locking (e.g., using SELECT ... FOR UPDATE in MySQL) locks the record during the edit process, preventing other users from modifying it until the lock is released. While effective, it can lead to deadlocks or performance bottlenecks with 500 users, especially if edits are frequent. Additionally, managing this at the database level requires custom SQL and increases administrative effort (e.g., monitoring locks), which the client wants to avoid. Appian prefers higher-level solutions like @Version over low-level database locking.
Option D (Design a process report and query to determine who opened the edit form first):This is impractical and inefficient. Building a custom report and query to track form opens adds complexity and administrative overhead. It doesn’t inherently prevent data loss and relies on manual resolution, conflicting with the client’s requirements.
The @Version annotation provides a robust, Appian-native solution that balances concurrency, data integrity, and ease of maintenance, making it the best fit.
You are taking your package from the source environment and importing it into the target environment.
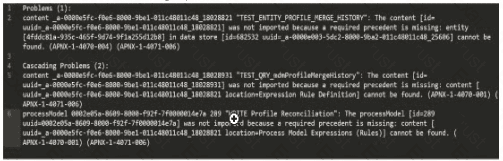
Review the errors encountered during inspection:
What is the first action you should take to Investigate the issue?
Check whether the object (UUID ending in 18028821) is included in this package
Check whether the object (UUD ending in 7t00000i4e7a) is included in this package
Check whether the object (UUID ending in 25606) is included in this package
Check whether the object (UUID ending in 18028931) is included in this package
The error log provided indicates issues during the package import into the target environment, with multiple objects failing to import due to missing precedents. The key error messages highlight specific UUIDs associated with objects that cannot be resolved. The first error listed states:
"‘TEST_ENTITY_PROFILE_MERGE_HISTORY’: The content [id=uuid-a-0000m5fc-f0e6-8000-9b01-011c48011c48, 18028821] was not imported because a required precedent is missing: entity [uuid=a-0000m5fc-f0e6-8000-9b01-011c48011c48, 18028821] cannot be found..."
According to Appian’s Package Deployment Best Practices, when importing a package, the first step in troubleshooting is to identify the root cause of the failure. The initial error in the log points to an entity object with a UUID ending in 18028821, which failed to import due to a missing precedent. This suggests that the object itself or one of its dependencies (e.g., a data store or related entity) is either missing from the package or not present in the target environment.
Option A (Check whether the object (UUID ending in 18028821) is included in this package): This is the correct first action. Since the first error references this UUID, verifying its inclusion in the package is the logical starting point. If it’s missing, the package export from the source environment was incomplete. If it’s included but still fails, the precedent issue (e.g., a missing data store) needs further investigation.
Option B (Check whether the object (UUID ending in 7t00000i4e7a) is included in this package): This appears to be a typo or corrupted UUID (likely intended as something like "7t000014e7a" or similar), and it’s not referenced in the primary error. It’s mentioned later in the log but is not the first issue to address.
Option C (Check whether the object (UUID ending in 25606) is included in this package): This UUID is associated with a data store error later in the log, but it’s not the first reported issue.
Option D (Check whether the object (UUID ending in 18028931) is included in this package): This UUID is mentioned in a subsequent error related to a process model or expression rule, but it’s not the initial failure point.
Appian recommends addressing errors in the order they appear in the log to systematically resolve dependencies. Thus, starting with the object ending in 18028821 is the priority.
Your application contains a process model that is scheduled to run daily at a certain time, which kicks off a user input task to a specified user on the 1st time zone for morning data collection. The time zone is set to the (default) pm!timezone. In this situation, what does the pm!timezone reflect?
The time zone of the server where Appian is installed.
The time zone of the user who most recently published the process model.
The default time zone for the environment as specified in the Administration Console.
The time zone of the user who is completing the input task.
Comprehensive and Detailed In-Depth Explanation:
In Appian, the pm!timezone variable is a process variable automatically available in process models, reflecting the time zone context for scheduled or time-based operations. Understanding its behavior is critical for scheduling tasks accurately, especially in scenarios like this where a process runs daily and assigns a user input task.
Option C (The default time zone for the environment as specified in the Administration Console):This is the correct answer. Per Appian’s Process Model documentation, when a process model uses pm!timezone and no custom time zone is explicitly set, it defaults to the environment’s time zone configured in the Administration Console (under System > Time Zone settings). For scheduled processes, such as one running “daily at a certain time,” Appian uses this default time zone to determine when the process triggers. In this case, the task assignment occurs based on the schedule, and pm!timezone reflects the environment’s setting, not the user’s location.
Option A (The time zone of the server where Appian is installed): This is incorrect. While the server’s time zone might influence underlying system operations, Appian abstracts this through the Administration Console’s time zone setting. The pm!timezone variable aligns with the configured environment time zone, not the raw server setting.
Option B (The time zone of the user who most recently published the process model): This is irrelevant. Publishing a process model does not tie pm!timezone to the publisher’s time zone. Appian’s scheduling is system-driven, not user-driven in this context.
Option D (The time zone of the user who is completing the input task): This is also incorrect. While Appian can adjust task display times in the user interface to the assigned user’s time zone (based on their profile settings), the pm!timezone in the process model reflects the environment’s default time zone for scheduling purposes, not the assignee’s.
For example, if the Administration Console is set to EST (Eastern Standard Time), the process will trigger daily at the specified time in EST, regardless of the assigned user’s location. The “1st time zone” phrasing in the question appears to be a typo or miscommunication, but it doesn’t change the fact that pm!timezone defaults to the environment setting.
Review the following result of an explain statement:

Which two conclusions can you draw from this?
The request is good enough to support a high volume of data. but could demonstrate some limitations if the developer queries information related to the product
The worst join is the one between the table order_detail and order.
The join between the tables order_detail, order and customer needs to be tine-tuned due to indices.
The join between the tables 0rder_detail and product needs to be fine-tuned due to Indices
The worst join is the one between the table order_detail and customer
The provided image shows the result of an EXPLAIN SELECT * FROM ... query, which analyzes the execution plan for a SQL query joining tables order_detail, order, customer, and product from a business_schema. The key columns to evaluate are rows and filtered, which indicate the number of rows processed and the percentage of rows filtered by the query optimizer, respectively. The results are:
order_detail: 155 rows, 100.00% filtered
order: 122 rows, 100.00% filtered
customer: 121 rows, 100.00% filtered
product: 1 row, 100.00% filtered
The rows column reflects the estimated number of rows the MySQL optimizer expects to process for each table, while filtered indicates the efficiency of the index usage (100% filtered means no rows are excluded by the optimizer, suggesting poor index utilization or missing indices). According to Appian’s Database Performance Guidelines and MySQL optimization best practices, high row counts with 100% filtered values indicate that the joins are not leveraging indices effectively, leading to full table scans, which degrade performance—especially with large datasets.
Option C (The join between the tables order_detail, order, and customer needs to be fine-tuned due to indices):This is correct. The tables order_detail (155 rows), order (122 rows), and customer (121 rows) all show significant row counts with 100% filtering. This suggests that the joins between these tables (likely via foreign keys like order_number and customer_number) are not optimized. Fine-tuning requires adding or adjusting indices on the join columns (e.g., order_detail.order_number and order.order_number) to reduce the row scan size and improve query performance.
Option D (The join between the tables order_detail and product needs to be fine-tuned due to indices):This is also correct. The product table has only 1 row, but the 100% filtered value on order_detail (155 rows) indicates that the join (likely on product_code) is not using an index efficiently. Adding an index on order_detail.product_code would help the optimizer filter rows more effectively, reducing the performance impact as data volume grows.
Option A (The request is good enough to support a high volume of data, but could demonstrate some limitations if the developer queries information related to the product): This is partially misleading. The current plan shows inefficiencies across all joins, not just product-related queries. With 100% filtering on all tables, the query is unlikely to scale well with high data volumes without index optimization.
Option B (The worst join is the one between the table order_detail and order): There’s no clear evidence to single out this join as the worst. All joins show 100% filtering, and the row counts (155 and 122) are comparable to others, so this cannot be conclusively determined from the data.
Option E (The worst join is the one between the table order_detail and customer): Similarly, there’s no basis to designate this as the worst join. The row counts (155 and 121) and filtering (100%) are consistent with other joins, indicating a general indexing issue rather than a specific problematic join.
The conclusions focus on the need for index optimization across multiple joins, aligning with Appian’s emphasis on database tuning for integrated applications.
You are required to create an integration from your Appian Cloud instance to an application hosted within a customer’s self-managed environment.
The customer’s IT team has provided you with a REST API endpoint to test with:
Which recommendation should you make to progress this integration?
Expose the API as a SOAP-based web service.
Deploy the API/service into Appian Cloud.
Add Appian Cloud’s IP address ranges to the customer network’s allowed IP listing.
Set up a VPN tunnel.
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, integrating an Appian Cloud instance with a customer’s self-managed (on-premises) environment requires addressing network connectivity, security, and Appian’s cloud architecture constraints. The provided endpoint is a REST API on an internal network, inaccessible directly from Appian Cloud due to firewall restrictions and lack of public exposure. Let’s evaluate each option:
A. Expose the API as a SOAP-based web service:Converting the REST API to SOAP isn’t a practical recommendation. The customer has provided a REST endpoint, and Appian fully supports REST integrations via Connected Systems and Integration objects. Changing the API to SOAP adds unnecessary complexity, development effort, and risks for the customer, with no benefit to Appian’s integration capabilities. Appian’s documentation emphasizes using the API’s native format (REST here), making this irrelevant.
B. Deploy the API/service into Appian Cloud:Deploying the customer’s API into Appian Cloud is infeasible. Appian Cloud is a managed PaaS environment, not designed to host customer applications or APIs. The API resides in the customer’s self-managed environment, and moving it would require significant architectural changes, violating security and operational boundaries. Appian’s integration strategy focuses on connecting to external systems, not hosting them, ruling this out.
C. Add Appian Cloud’s IP address ranges to the customer network’s allowed IP listing:This approach involves whitelisting Appian Cloud’s IP ranges (available in Appian documentation) in the customer’s firewall to allow direct HTTP/HTTPS requests. However, Appian Cloud’s IPs are dynamic and shared across tenants, making this unreliable for long-term integrations—changes in IP ranges could break connectivity. Appian’s best practices discourage relying on IP whitelisting for cloud-to-on-premises integrations due to this limitation, favoring secure tunnels instead.
D. Set up a VPN tunnel:This is the correct recommendation. A Virtual Private Network (VPN) tunnel establishes a secure, encrypted connection between Appian Cloud and the customer’s self-managed network, allowing Appian to access the internal REST API Appian supports VPNs for cloud-to-on-premises integrations, and this approach ensures reliability, security, and compliance with network policies. The customer’s IT team can configure the VPN, and Appian’s documentation recommends this for such scenarios, especially when dealing with internal endpoints.
Conclusion: Setting up a VPN tunnel (D) is the best recommendation. It enables secure, reliable connectivity from Appian Cloud to the customer’s internal API, aligning with Appian’s integration best practices for cloud-to-on-premises scenarios.
What are two advantages of having High Availability (HA) for Appian Cloud applications?
An Appian Cloud HA instance is composed of multiple active nodes running in different availability zones in different regions.
Data and transactions are continuously replicated across the active nodes to achieve redundancy and avoid single points of failure.
A typical Appian Cloud HA instance is composed of two active nodes.
In the event of a system failure, your Appian instance will be restored and available to your users in less than 15 minutes, having lost no more than the last 1 minute worth of data.
Comprehensive and Detailed In-Depth Explanation:
High Availability (HA) in Appian Cloud is designed to ensure that applications remain operational and data integrity is maintained even in the face of hardware failures, network issues, or other disruptions. Appian’s Cloud Architecture and HA documentation outline the benefits, focusing on redundancy, minimal downtime, and data protection. The question asks for two advantages, and the options must align with these core principles.
Option B (Data and transactions are continuously replicated across the active nodes to achieve redundancy and avoid single points of failure):This is a key advantage of HA. Appian Cloud HA instances use multiple active nodes to replicate data and transactions in real-time across the cluster. This redundancy ensures that if one node fails, others can take over without data loss, eliminating single points of failure. This is a fundamental feature of Appian’s HA setup, leveraging distributed architecture to enhance reliability, as detailed in the Appian Cloud High Availability Guide.
Option D (In the event of a system failure, your Appian instance will be restored and available to your users in less than 15 minutes, having lost no more than the last 1 minute worth of data):This is another significant advantage. Appian Cloud HA is engineered to provide rapid recovery and minimal data loss. The Service Level Agreement (SLA) and HA documentation specify that in the case of a failure, the system failover is designed to complete within a short timeframe (typically under 15 minutes), with data loss limited to the last minute due to synchronous replication. This ensures business continuity and meets stringent uptime and data integrity requirements.
Option A (An Appian Cloud HA instance is composed of multiple active nodes running in different availability zones in different regions):This is a description of the HA architecture rather than an advantage. While running nodes across different availability zones and regions enhances fault tolerance, the benefit is the resulting redundancy and availability, which are captured in Options B and D. This option is more about implementation than a direct user or operational advantage.
Option C (A typical Appian Cloud HA instance is composed of two active nodes):This is a factual statement about the architecture but not an advantage. The number of nodes (typically two or more, depending on configuration) is a design detail, not a benefit. The advantage lies in what this setup enables (e.g., redundancy and quick recovery), as covered by B and D.
The two advantages—continuous replication for redundancy (B) and fast recovery with minimal data loss (D)—reflect the primary value propositions of Appian Cloud HA, ensuring both operational resilience and data integrity for users.
You have 5 applications on your Appian platform in Production. Users are now beginning to use multiple applications across the platform, and the client wants to ensure a consistent user experience across all applications.
You notice that some applications use rich text, some use section layouts, and others use box layouts. The result is that each application has a different color and size for the header.
What would you recommend to ensure consistency across the platform?
Create constants for text size and color, and update each section to reference these values.
In the common application, create a rule that can be used across the platform for section headers, and update each application to reference this new rule.
In the common application, create one rule for each application, and update each application to reference its respective rule.
In each individual application, create a rule that can be used for section headers, and update each application to reference its respective rule.
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, ensuring a consistent user experience across multiple applications on the Appian platform involves centralizing reusable components and adhering to Appian’s design governance principles. The client’s concern about inconsistent headers (e.g., different colors, sizes, layouts) across applications using rich text, section layouts, and box layouts requires a scalable, maintainable solution. Let’s evaluate each option:
A. Create constants for text size and color, and update each section to reference these values:Using constants (e.g., cons!TEXT_SIZE and cons!HEADER_COLOR) is a good practice for managing values, but it doesn’t address layout consistency (e.g., rich text vs. section layouts vs. box layouts). Constants alone can’t enforce uniform header design across applications, as they don’t encapsulate layout logic (e.g., a!sectionLayout() vs. a!richTextDisplayField()). This approach would require manual updates to each application’s components, increasing maintenance overhead and still risking inconsistency. Appian’s documentation recommends using rules for reusable UI components, not just constants, making this insufficient.
B. In the common application, create a rule that can be used across the platform for section headers, and update each application to reference this new rule:This is the best recommendation. Appian supports a “common application” (often called a shared or utility application) to store reusable objects like expression rules, which can define consistent header designs (e.g., rule!CommonHeader(size: "LARGE", color: "PRIMARY")). By creating a single rule for headers and referencing it across all 5 applications, you ensure uniformity in layout, color, and size (e.g., using a!sectionLayout() or a!boxLayout() consistently). Appian’s design best practices emphasize centralizing UI components in a common application to reduce duplication, enforce standards, and simplify maintenance—perfect for achieving a consistent user experience.
C. In the common application, create one rule for each application, and update each application to reference its respective rule:This approach creates separate header rules for each application (e.g., rule!App1Header, rule!App2Header), which contradicts the goal of consistency. While housed in the common application, it introduces variability (e.g., different colors or sizes per rule), defeating the purpose. Appian’s governance guidelines advocate for a single, shared rule to maintain uniformity, making this less efficient and unnecessary.
D. In each individual application, create a rule that can be used for section headers, and update each application to reference its respective rule:Creating separate rules in each application (e.g., rule!App1Header in App 1, rule!App2Header in App 2) leads to duplication and inconsistency, as each rule could differ in design. This approach increases maintenance effort and risks diverging styles, violating the client’s requirement for a “consistent user experience.” Appian’s best practices discourage duplicating UI logic, favoring centralized rules in a common application instead.
Conclusion: Creating a rule in the common application for section headers and referencing it across the platform (B) ensures consistency in header design (color, size, layout) while minimizing duplication and maintenance. This leverages Appian’s application architecture for shared objects, aligning with Lead Developer standards for UI governance.
You are developing a case management application to manage support cases for a large set of sites. One of the tabs in this application s site Is a record grid of cases, along with Information about the site corresponding to that case. Users must be able to filter cases by priority level and status.
You decide to create a view as the source of your entity-backed record, which joins the separate case/site tables (as depicted in the following Image).

Which three column should be indexed?
site_id
status
name
modified_date
priority
case_id
Indexing columns can improve the performance of queries that use those columns in filters, joins, or order by clauses. In this case, the columns that should be indexed are site_id, status, and priority, because they are used for filtering or joining the tables. Site_id is used to join the case and site tables, so indexing it will speed up the join operation. Status and priority are used to filter the cases by the user’s input, so indexing them will reduce the number of rows that need to be scanned. Name, modified_date, and case_id do not need to be indexed, because they are not used for filtering or joining. Name and modified_date are only used for displaying information in the record grid, and case_id is only used as a unique identifier for each record. Verified References: Appian Records Tutorial, Appian Best Practices
As an Appian Lead Developer, optimizing a database view for an entity-backed record grid requires indexing columns frequently used in queries, particularly for filtering and joining. The scenario involves a record grid displaying cases with site information, filtered by “priority level” and “status,” and joined via the site_id foreign key. The image shows two tables (site and case) with a relationship via site_id. Let’s evaluate each column based on Appian’s performance best practices and query patterns:
A. site_id:This is a primary key in the site table and a foreign key in the case table, used for joining the tables in the view. Indexing site_id in the case table (and ensuring it’s indexed in site as a PK) optimizes JOIN operations, reducing query execution time for the record grid. Appian’s documentation recommends indexing foreign keys in large datasets to improve query performance, especially for entity-backed records. This is critical for the join and must be included.
B. status:Users filter cases by “status” (a varchar column in the case table). Indexing status speeds up filtering queries (e.g., WHERE status = 'Open') in the record grid, particularly with large datasets. Appian emphasizes indexing columns used in WHERE clauses or filters to enhance performance, making this a key column for optimization. Since status is a common filter, it’s essential.
C. name:This is a varchar column in the site table, likely used for display (e.g., site name in the grid). However, the scenario doesn’t mention filtering or sorting by name, and it’s not part of the join or required filters. Indexing name could improve searches if used, but it’s not a priority given the focus on priority and status filters. Appian advises indexing only frequently queried or filtered columns to avoid unnecessary overhead, so this isn’t necessary here.
D. modified_date:This is a date column in the case table, tracking when cases were last updated. While useful for sorting or historical queries, the scenario doesn’t specify filtering or sorting by modified_date in the record grid. Indexing it could help if used, but it’s not critical for the current requirements. Appian’s performance guidelines prioritize indexing columns in active filters, making this lower priority than site_id, status, and priority.
E. priority:Users filter cases by “priority level” (a varchar column in the case table). Indexing priority optimizes filtering queries (e.g., WHERE priority = 'High') in the record grid, similar to status. Appian’s documentation highlights indexing columns used in WHERE clauses for entity-backed records, especially with large datasets. Since priority is a specified filter, it’s essential to include.
F. case_id:This is the primary key in the case table, already indexed by default (as PKs are automatically indexed in most databases). Indexing it again is redundant and unnecessary, as Appian’s Data Store configuration relies on PKs for unique identification but doesn’t require additional indexing for performance in this context. The focus is on join and filter columns, not the PK itself.
Conclusion: The three columns to index are A (site_id), B (status), and E (priority). These optimize the JOIN (site_id) and filter performance (status, priority) for the record grid, aligning with Appian’s recommendations for entity-backed records and large datasets. Indexing these columns ensures efficient querying for user filters, critical for the application’s performance.
You are in a backlog refinement meeting with the development team and the product owner. You review a story for an integration involving a third-party system. A payload will be sent from the Appian system through the integration to the third-party system. The story is 21 points on a Fibonacci scale and requires development from your Appian team as well as technical resources from the third-party system. This item is crucial to your project’s success. What are the two recommended steps to ensure this story can be developed effectively?
Acquire testing steps from QA resources.
Identify subject matter experts (SMEs) to perform user acceptance testing (UAT).
Maintain a communication schedule with the third-party resources.
Break down the item into smaller stories.
Comprehensive and Detailed In-Depth Explanation:
This question involves a complex integration story rated at 21 points on the Fibonacci scale, indicating significant complexity and effort. Appian Lead Developer best practices emphasize effective collaboration, risk mitigation, and manageable development scopes for such scenarios. The two most critical steps are:
Option C (Maintain a communication schedule with the third-party resources):Integrations with third-party systems require close coordination, as Appian developers depend on external teams for endpoint specifications, payload formats, authentication details, and testing support. Establishing a regular communication schedule ensures alignment on requirements, timelines, and issue resolution. Appian’s Integration Best Practices documentation highlights the importance of proactive communication with external stakeholders to prevent delays and misunderstandings, especially for critical project components.
Option D (Break down the item into smaller stories):A 21-point story is considered large by Agile standards (Fibonacci scale typically flags anything above 13 as complex). Appian’s Agile Development Guide recommends decomposing large stories into smaller, independently deliverable pieces to reduce risk, improve testability, and enable iterative progress. For example, the integration could be split into tasks like designing the payload structure, building the integration object, and testing the connection—each manageable within a sprint. This approach aligns with the principle of delivering value incrementally while maintaining quality.
Option A (Acquire testing steps from QA resources): While QA involvement is valuable, this step is more relevant during the testing phase rather than backlog refinement or development preparation. It’s not a primary step for ensuring effective development of the story.
Option B (Identify SMEs for UAT): User acceptance testing occurs after development, during the validation phase. Identifying SMEs is important but not a key step in ensuring the story is developed effectively during the refinement and coding stages.
By choosing C and D, you address both the external dependency (third-party coordination) and internal complexity (story size), ensuring a smoother development process for this critical integration.
You need to design a complex Appian integration to call a RESTful API. The RESTful API will be used to update a case in a customer’s legacy system.
What are three prerequisites for designing the integration?
Define the HTTP method that the integration will use.
Understand the content of the expected body, including each field type and their limits.
Understand whether this integration will be used in an interface or in a process model.
Understand the different error codes managed by the API and the process of error handling in Appian.
Understand the business rules to be applied to ensure the business logic of the data.
Comprehensive and Detailed In-Depth Explanation:
As an Appian Lead Developer, designing a complex integration to a RESTful API for updating a case in a legacy system requires a structured approach to ensure reliability, performance, and alignment with business needs. The integration involves sending a JSON payload (implied by the context) and handling responses, so the focus is on technical and functional prerequisites. Let’s evaluate each option:
A. Define the HTTP method that the integration will use:This is a primary prerequisite. RESTful APIs use HTTP methods (e.g., POST, PUT, GET) to define the operation—here, updating a case likely requires PUT or POST. Appian’s Connected System and Integration objects require specifying the method to configure the HTTP request correctly. Understanding the API’s method ensures the integration aligns with its design, making this essential for design. Appian’s documentation emphasizes choosing the correct HTTP method as a foundational step.
B. Understand the content of the expected body, including each field type and their limits:This is also critical. The JSON payload for updating a case includes fields (e.g., text, dates, numbers), and the API expects a specific structure with field types (e.g., string, integer) and limits (e.g., max length, size constraints). In Appian, the Integration object requires a dictionary or CDT to construct the body, and mismatches (e.g., wrong types, exceeding limits) cause errors (e.g., 400 Bad Request). Appian’s best practices mandate understanding the API schema to ensure data compatibility, making this a key prerequisite.
C. Understand whether this integration will be used in an interface or in a process model:While knowing the context (interface vs. process model) is useful for design (e.g., synchronous vs. asynchronous calls), it’s not a prerequisite for the integration itself—it’s a usage consideration. Appian supports integrations in both contexts, and the integration’s design (e.g., HTTP method, body) remains the same. This is secondary to technical API details, so it’s not among the top three prerequisites.
D. Understand the different error codes managed by the API and the process of error handling in Appian:This is essential. RESTful APIs return HTTP status codes (e.g., 200 OK, 400 Bad Request, 500 Internal Server Error), and the customer’s API likely documents these for failure scenarios (e.g., invalid data, server issues). Appian’s Integration objects can handle errors via error mappings or process models, and understanding these codes ensures robust error handling (e.g., retry logic, user notifications). Appian’s documentation stresses error handling as a core design element for reliable integrations, making this a primary prerequisite.
E. Understand the business rules to be applied to ensure the business logic of the data:While business rules (e.g., validating case data before sending) are important for the overall application, they aren’t a prerequisite for designing the integration itself—they’re part of the application logic (e.g., process model or interface). The integration focuses on technical interaction with the API, not business validation, which can be handled separately in Appian. This is a secondary concern, not a core design requirement for the integration.
Conclusion: The three prerequisites are A (define the HTTP method), B (understand the body content and limits), and D (understand error codes and handling). These ensure the integration is technically sound, compatible with the API, and resilient to errors—critical for a complex RESTful API integration in Appian.
Copyright © 2014-2026 Examstrust. All Rights Reserved